

Comment la science des données fait-elle pour rendre pertinent et réaliste le langage artificiel des chatbots et autres voicebots ?
cKiou a voulu approfondir notre compréhension du langage de nos interlocuteurs artificiels : chatbots, voicebots, callbots et autres bots conversationnels. Car même si nous savons bien que ce ne sont pas de « vrais Humains », avec notre tendance innée à l’anthropomorphisme, nous n’entendons pas spontanément que nous dialoguons avec des algorithmes ! D’autant que des Humains, des vrais cette fois, s’emploient à rendre ce langage artificiel confondant de réalisme ! C’est le cas de Carole Lailler, Dr en sciences du langage, spécialiste de morphosyntaxe. Elle nous a récemment expliqué comment les sciences du langage font parler les Intelligences Artificielles, à grand renfort de « données préparées, lissées… ». Carole revient lever le voile sur cette mystérieuse science des données…
cKiou infiltre la « science des données » indispensable au langage artificiel
 – Hi, cKiou était impatiente d’échanger de nouveau avec toi ! J’ai encore des questions pour toi… Pour commencer, tu avais mis l’accent sur l’importance des données à l’origine du langage des Assistants conversationnels en disant qu’il faut « nourrir les systèmes avec les meilleures données ». Déjà pour les Humains, la nutrition est une science complexe, alors pour les Algorithmes… Je suis curieuse de savoir comment ça se passe concrètement !
– Hi, cKiou était impatiente d’échanger de nouveau avec toi ! J’ai encore des questions pour toi… Pour commencer, tu avais mis l’accent sur l’importance des données à l’origine du langage des Assistants conversationnels en disant qu’il faut « nourrir les systèmes avec les meilleures données ». Déjà pour les Humains, la nutrition est une science complexe, alors pour les Algorithmes… Je suis curieuse de savoir comment ça se passe concrètement !
– Ta question est légitime cKiou, et comme je suis gourmande, je vais commencer par détailler le menu ! Mais rassure-toi, point de magie, juste de la logique et quelques corpus bien préparés. Lorsqu’on parle de nourrir les systèmes de reconnaissance de la parole (ou de traduction ou de tâches dites de NLP pour reconnaître les éléments porteurs de sens), on s’intéresse en réalité aux techniques de Machine Learning. Le système est construit en amont avec des données d’apprentissage qui lui permettent d’avoir une connaissance du langage cible suffisante pour ensuite faire fonctionner ses algorithmes et parvenir à transcrire le son de ta voix, à traduire dans une autre langue ou à relever les noms des gens, lieux et dates dans ce que tu dis.
Ainsi, si je prends l’exemple d’un système de reconnaissance de la parole (qui s’approche de SIRI, même s’il n’a pas exactement les mêmes algo ni les mêmes architectures d’apprentissage), il nous faut des données écrites et sonores et un joli système (pas forcément construit sur du deep learning mais c’est intéressant aussi) construit sur des probabilités.

Carole Lailler, Dr en sciences du langage, spécialiste de morphosyntaxe et consultante en IA au sein de Scribe Conseil
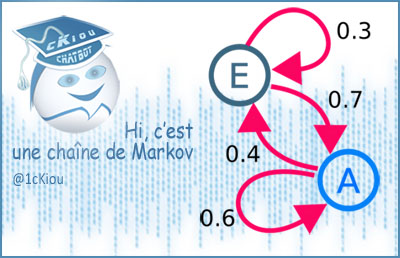
Chaîne de Markov, un processus construit sur des probabilités où chaque résultat possible est mesuré par un nombre…
D’une chaîne de Markov à l’orange bleue… Anticiper la probabilité du langage humain
En effet, ce type d’outils fonctionne sur une logique statistique (chaînes de Markov si tu aimes) qui s’appuie sur la probabilité d’existence d’un mot connaissant son contexte.
Si je te dis « le pommier est un arbre qui produit des… », tu finiras ma phrase en me disant « pommes ». Ce sera un peu plus difficile si tu ne connais pas le poète Eluard et que je te dis « la Terre est bleue comme une… ». Tu ne sauras peut-être pas qu’il faut me répondre « orange ». Dans ce dernier cas, le poète fait preuve de son génie et recourt à une forme de licence poétique en jouant avec les mots et les liens que nous connaissons en tant qu’Humains. Si toi, ou un système, ne connaissez pas ce trait de culture, vous allez être embêtés car il n’est ni courant ni probable de dire cela.
Un modèle de langage parlé pour bot conversationnel… Jeu de « data construction » !
Quand je construis un système, sans forcément tout faire par un réseau de neurones même si on les embarque aussi, je construis trois bases de connaissances :
– le modèle acoustique modélise les sons d’une langue, y compris en contexte… Pense aux accents des régions de France, par exemple. Et aux difficultés qui sont celles du français (les liaisons, les hiatus qu’on évite, les lettres qu’on ne prononce pas ou plus) et aux particularités liées à la spontanéité d’un discours oral (toutes ces petites « disfluences » comme les « euh », les « bah »… qui accompagnent notre pensée qui s’architecture). Je le fais avec les données audios enregistrées de façon à ce que le système apprenne ce que sont les suites de phonèmes (sons) de la langue sur laquelle je travaille, et qu’il en profite pour acquérir toutes les subtilités et les variétés possibles grâce aux locuteurs…

Le système de construction du langage doit pouvoir tenir compte du contexte…
– Il faut également construire un modèle de langage qui reprend les suites de mots correspondant aux sons entendus, et même un peu plus. Et là, le système apprend la grammaire, la structure de la langue. Il ne cherche rien, ne se fait pas d’idée… Il apprend sans jugement… La vraie difficulté est que le Français est une langue où le contexte joue un rôle fondamental. « La belle porte le voile » possède deux sens et ce n’est que parce que tu connaîtras le contexte (dit d’énonciation) que tu sauras si j’évoque une jolie femme ou une partie de l’huisserie d’une maison ! De même, si je te parle de regard, tu imagines tout de suite la noirceur de mes yeux (contrairement à toi) mais si je te parle en même temps du plombier, tu peux légitimement avoir un doute et te dire que je te parle de tuyaux et de canalisations…
– Puis on lui ajoute un dictionnaire de phonétisation qui fait correspondre aux mots les différentes façons de les prononcer. Car il faut penser aux variations entre les locuteurs et aux possibles erreurs, voire aux accents également : pense aux différentes marques de téléphone dont on peut parler et que personne ne sait prononcer correctement, pense à ce cher [peneu] de nos amis marseillais quand ils parlent de ce qui fait rouler leur voiture…
La science des données d’apprentissage du langage… des données propres, efficaces et respectueuses !
Ces données d’apprentissage, bien sûr, on les nettoie : on fait en sorte que le système puisse apprendre sur une base propre et efficace : les dates sont toutes mises sur le même format par exemple, les espaces fantaisistes enlevées, les smileys isolés, les chiffres écrits en toutes lettres… Il ne s’agit pas de trahir les données mais de faire en sorte que les systèmes les apprennent toutes pour ce qu’elles sont et sur un pied d’égalité.
Plus on aura un vocabulaire différent du français courant à transcrire, plus on essaiera d’aider les algorithmes en donnant aux systèmes des données en rapport avec la langue cible :
– vocabulaire terminologique (pense aux comptes-rendus des médecins par exemple, ou aux discours de spécialistes de thermodynamique des fluides)
– langue très spontanée ou avec des mots d’argot ou étrangers
On essaiera, grâce à des calculs (la mesure de perplexité notamment pour les spécialistes) et des analyses, de trouver les bons corpus, de pondérer intelligemment. Ce n’est pas toujours facile et plus on a de données, plus on peut recourir aux fameuses architectures deep learning qui vont apprendre plus vite. Mais il faut toujours un travail de base minutieux et conscient, éthique évidemment, sur les données d’entrée.
Il va sans dire que plus le langage utilisé est poétique, peu probable, plus le système peinera. Plus on évoquera des réalités logiques et fonctionnelles, plus ce sera facile !
Passer du langage naturel à une analyse normée et thématique
– Hi, cKiou a été interpellée par l’exemple des contributions au « grand débat » et la masse de données de langage (68 millions de mots) qui ont dû être analysées en deux semaines. Rien que d’y penser ça me donne mal à la tête 😉 ! Sérieusement, plus que le volume impressionnant, ce qui interpelle mes petits algorithmes, c’est comment un système d’IA peut « donner du sens » aux mots, sachant que les textes rédigés par des Humains peuvent utiliser un vocabulaire, des locutions, des tournures très « originales » ?
– Comme je te le disais, cKiou, c’est d’abord une question de préparation de données, de normalisation : le but est de faire en sorte de vérifier que tous les éléments de discours vont pouvoir être pris en compte et ne pas être « pollués » ou non comptés…
Ensuite, c’est d’abord et avant tout une question de comptage de mots, voire de radicaux, voire de ngrams (souvent des bi et trigrammes pour le français, c’est-à-dire des ensembles de 2 ou 3 mots). Bien sûr des calculs et autres distances sont faits pour cartographier les éléments les plus présents, les moins, pour réussir à donner les thématiques, etc.
Ce qu’il faut retenir, c’est qu’une fois les données nettoyées et constituées en corpus, on compte, en isolant si besoin les mots-outils les plus courants (ceux qui ne sont là que pour aider à la construction grammaticale de la phrase), on compte, on compte, on compte. Éventuellement, on peut également étiqueter à la main quelques sous-ensembles pour mieux généraliser des étiquettes utiles et recommencer à compter !

Petit éclairage sémantique
Callbot
Chatbot utilisé sur le canal téléphonique
Voicebot
Assistant vocal intégré au sein des enceintes (Siri, Alexa, Google Home…) pour répondre oralement à nos questions
NLP
Traitement automatique du langage naturel
Machine Learning
Apprentissage automatique, se fonde sur des approches statistiques pour permettre aux ordinateurs « d’apprendre » à partir de données

Science des données : langage et culture, deux mots unis pour le meilleur et pour le pire !
 – Hi, cKiou a effectivement remarqué qu’il y a de grandes différences dans la façon de s’exprimer selon le milieu socioculturel, selon les régions, selon les générations… Par exemple, si tu travailles sur un corpus de données pour un robot, tu devras sûrement différencier selon que le robot est destiné à intégrer un service de pédiatrie ou une maison de retraite, voire anticiper les réactions psychoaffectives générationnelles ?
– Hi, cKiou a effectivement remarqué qu’il y a de grandes différences dans la façon de s’exprimer selon le milieu socioculturel, selon les régions, selon les générations… Par exemple, si tu travailles sur un corpus de données pour un robot, tu devras sûrement différencier selon que le robot est destiné à intégrer un service de pédiatrie ou une maison de retraite, voire anticiper les réactions psychoaffectives générationnelles ?

Carole Lailler
– Évidemment, tu as tout compris ! Mais plutôt que de différencier, je vais parler d’adaptation. L’idée c’est d’adapter les apprentissages des systèmes avec des corpus dédiés. Soit j’ai la chance d’avoir des données conversationnelles transcrites et je vais les cartographier avec des outils dédiés pour réussir à capturer ce qui fait l’essence même de cet ensemble de locuteurs, leurs habitudes, leurs tics, leur vocabulaire. Soit je n’ai pas de chance et je vais travailler ces variations manuellement en construisant des paradigmes (= un ensemble où chaque élément a la même valeur que ses « collègues » et au sein duquel, lorsqu’on choisit un candidat, on exclut les autres) autour d’intentions. Plus clairement, sur un énoncé donné, je vais en écrire beaucoup d’autres qui ont la même valeur langagière, mais qui sont construits différemment. J’adore faire ça ; je me mets à la place des locuteurs, je bouge les structures, insère des disfluences, joue sur les synonymes, les expressions. C’est mieux que du tricot 😉 !
– Hi, cKiou aussi trouve passionnant de faire parler les algorithmes avec des multitudes de données ! Et percer les secrets de l’expression humaine pour les transmettre aux Intelligences Artificielles, c’est un métier d’avenir, tu ne crois pas ?
– Évidemment ! Oui cKiou, la science des données et du langage est un métier d’avenir. C’est en respectant et les usages et la réalité des diversités langagières que les outils d’IA seront efficaces et élégants !
Carole Lailler, Dr en sciences du langage, spécialiste de morphosyntaxe et consultante en IA au sein de Scribe Conseil
- Découvrir les premières étapes de la vie de cKiou
- Les contributions des marraines et parrains de cKiou
Et sur Twitter :
Pour ne pas manquer les prochains apprentissages de cKiou :
(les adresses e-mails ne sont ni affichées ni cédées à des tiers)
On ne se rend pas naturellement compte de l’importance du travail en amont du langage des robots. C’est sûr que distinguer les différentes interprétations des mots en fonction du contexte (l’exemple du regard ou celui de l’orange bleue), c’est pas évident. Je suis sûr que beaucoup d’élèves humains font des contresens.
Merci Françoise Halper et votre géniale cKiou ainsi que Carole Lailler pour cet éclairage très intéressant.
Merci c’est très intéressant. On voit bien, avec cette part de travail humain en amont sur les données, ce que vous appelez le « jeu de data construction ». Et aussi que si l’on n’y prend garde, les biais de toutes sortes (sexistes et autres) peuvent s’installer. Voilà qui rend l’instauration d’une éthique et une transparence de l’IA encore plus prégnante.